Tensorflow, MNIST and your own handwritten digits
Creation date: 2015-11-17

There are a lot of articles about MNIST and how to learn handwritten digits. So this one will be just another one? Nope, I'll use the newest available library Tensorflow by Google, but they have there own MNIST article inside there tutorial section here.
Come on, so this one will be just another one? Really nope, I didn't find any article which describes how to recognize the digits as we normally write them. All digits inside MNIST looks like this
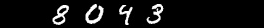
but no one writes with a perfect white pen on a black background. You will use your camera and make a photo where the digit isn't in the center. That will look something like this:

If you use that as the input for your neural net, you will get some random results. The last part of every article about MNIST is about the accuracy which is something around >85% and you will get something like 10% (random).
How to get this accuracy with your own handwritten digits?
The MNIST dataset - a small overview
The MNIST dataset is a dataset of handwritten digits which includes 60,000 examples for the training phase and 10,000 images of handwritten digits in the test set. All images are size normalized to fit in a 20x20 pixel box and there are centered in a 28x28 image using the center of mass. These are important information for our preprocessing.
Tensorflow - Library for machine learning by Google
Tensorflow is an open source software library for machine learning which provides a flexible architecture and can run on the GPU and CPU and on many different devices including mobile devices.
It's helpful to read the MNIST tutorial directly on their side here.
Here is the code from the tutorial with some comments.
"""
import tensorflow and the input_data script
"""
import tensorflow as tf
import input_dataYou can download the input_data class here.
# create a MNIST_data folder with the MNIST dataset if necessary
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
"""
a placeholder for our image data:
None stands for an unspecified number of images
784 = 28*28 pixel
"""
x = tf.placeholder("float", [None, 784])
# we need our weights for our neural net
W = tf.Variable(tf.zeros([784,10]))
# and the biases
b = tf.Variable(tf.zeros([10]))
"""
softmax provides a probability based output
we need to multiply the image values x and the weights
and add the biases
(the normal procedure, explained in previous articles)
"""
y = tf.nn.softmax(tf.matmul(x,W) + b)
"""
y_ will be filled with the real values
which we want to train (digits 0-9)
for an undefined number of images
"""
y_ = tf.placeholder("float", [None,10])
"""
we use the cross_entropy function
which we want to minimize to improve our model
"""
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
"""
use a learning rate of 0.01
to minimize the cross_entropy error
"""
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# initialize all variables
init = tf.initialize_all_variables()
# create a session
sess = tf.Session()
sess.run(init)
# use 1000 batches with a size of 100 each to train our net
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
# run the train_step function with the given image values (x) and the real output (y_)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
"""
Let's get the accuracy of our model:
our model is correct if the index with the highest y value
is the same as in the real digit vector
The mean of the correct_prediction gives us the accuracy.
We need to run the accuracy function
with our test set (mnist.test)
We use the keys "images" and "labels" for x and y_
"""
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})This gives us an accuracy of about 91% which is pretty good for a small number of lines. But now we want to use it to play with our real data.
Preprocessing
The most basic approach is to scale all our handwritten digits to a 28x28 pixel image.
# create an array where we can store our 4 pictures
images = np.zeros((4,784))
# and the correct values
correct_vals = np.zeros((4,10))
# we want to test our images which you saw at the top of this page
i = 0
for no in [8,0,4,3]:
# read the image
gray = cv2.imread("img/blog/own_"+str(no)+".png", cv2.CV_LOAD_IMAGE_GRAYSCALE)
# resize the images and invert it (black background)
gray = cv2.resize(255-gray, (28, 28))
# save the processed images
cv2.imwrite("pro-img/image_"+str(no)+".png", gray)
"""
all images in the training set have an range from 0-1
and not from 0-255 so we divide our flatten images
(a one dimensional vector with our 784 pixels)
to use the same 0-1 based range
"""
flatten = gray.flatten() / 255.0
"""
we need to store the flatten image and generate
the correct_vals array
correct_val for the first digit (9) would be
[0,0,0,0,0,0,0,0,0,1]
"""
images[i] = flatten
correct_val = np.zeros((10))
correct_val[no] = 1
correct_vals[i] = correct_val
i += 1
"""
the prediction will be an array with four values,
which show the predicted number
"""
prediction = tf.argmax(y,1)
"""
we want to run the prediction and the accuracy function
using our generated arrays (images and correct_vals)
"""
print sess.run(prediction, feed_dict={x: images, y_: correct_vals})
print sess.run(accuracy, feed_dict={x: images, y_: correct_vals})If you run this basic approach you will get an accuracy of 0.25 and a prediction of something like [3 5 2 3] The net will be slightly different anytime you run the script so it can be something different, but yeah it's wrong most of the time.

Okay it's quite obvious that the images doesn't look like the trained ones. These are white digits on a gray background and not on a black one.
Therefore we need to add the following line:
(thresh, gray) = cv2.threshold(gray, 128, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)directly after we resize the image.
gray = cv2.resize(255-gray, (28, 28))
This gives us an accuracy of 50%, because the 0 is pretty good centered.
Now let's go back to the first sentences of the "MNIST" section in this entry.
All images are size normalized to fit in a 20x20 pixel box and there are centered in a 28x28 image using the center of mass.
These are important information for our preprocessing.
First we want to fit the images into this 20x20 pixel box. Therefore we need to remove every row and column at the sides of the image which are completely black.
while np.sum(gray[0]) == 0:
gray = gray[1:]
while np.sum(gray[:,0]) == 0:
gray = np.delete(gray,0,1)
while np.sum(gray[-1]) == 0:
gray = gray[:-1]
while np.sum(gray[:,-1]) == 0:
gray = np.delete(gray,-1,1)
rows,cols = gray.shapeNow we resize our outer box to fit it into a 20x20 box. Let's calculate the resize factor:
if rows > cols:
factor = 20.0/rows
rows = 20
cols = int(round(cols*factor))
gray = cv2.resize(gray, (cols,rows))
else:
factor = 20.0/cols
cols = 20
rows = int(round(rows*factor))
gray = cv2.resize(gray, (cols, rows))But at the end we need a 28x28 pixel image so we add the missing black rows and columns using the np.lib.pad function which adds 0s to the sides.
colsPadding = (int(math.ceil((28-cols)/2.0)),int(math.floor((28-cols)/2.0)))
rowsPadding = (int(math.ceil((28-rows)/2.0)),int(math.floor((28-rows)/2.0)))
gray = np.lib.pad(gray,(rowsPadding,colsPadding),'constant')In our really small test set of only four images we are getting an accuracy of 50%.
The next step is to shift the inner box so that it is centered using the center of mass.
We need two functions for this last step. The first one will get the center_of_mass which is a function in the library ndimage from scipy so we need to add from scipy import ndimage at the beginning of our code.
def getBestShift(img):
cy,cx = ndimage.measurements.center_of_mass(img)
rows,cols = img.shape
shiftx = np.round(cols/2.0-cx).astype(int)
shifty = np.round(rows/2.0-cy).astype(int)
return shiftx,shiftyThe second functions shifts the image in the given directions. The warpAffine function is explained here.
This is our transformation matrix to shift the image.
\[ M = \begin{pmatrix} 1 & 0 & s_x \\ 0 & 1 & s_y \end{pmatrix} \]def shift(img,sx,sy):
rows,cols = img.shape
M = np.float32([[1,0,sx],[0,1,sy]])
shifted = cv2.warpAffine(img,M,(cols,rows))
return shiftedafter our last line in the for loop: gray = np.lib.pad(gray,(rowsPadding,colsPadding),'constant') we need to add two lines to use the defined functions:
shiftx,shifty = getBestShift(gray)
shifted = shift(gray,shiftx,shifty)
gray = shifted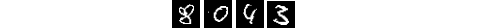
And finally we have a accuracy of 100%. Of course we used a very small test set, but you can see the changes after the preprocessing steps.
In general it's easier to normalize the data for a neural net, because you will need way less images to train such a network.
You can download all the code on my OpenSourcES GitHub repo.
Next article
You might be interested how to recognize whole numbers anywhere on an image and not only a single digit. Enjoy this blog entry!
If you want to be up to date about new things on here you can follow me on Twitter or if you enjoy Reddit you can subscribe to my subreddit.
If you enjoy the blog in general please consider a donation via Patreon. You can read my posts earlier than everyone else and keep this blog running.
Want to be updated? Consider subscribing on Patreon for free
