Bugs and Benchmarks
Creation date: 2020-05-11

This is part 22 of an ongoing series about: How to build a constraint solver? You might want to check out earlier posts if you're new but this part is one of the parts that can be read by itself (mostly). See first post for a list of other posts in this series.
In short: I'm creating a constraint solver from scratch in Julia. You can follow the project on my GitHub repo. Whenever I add something not too small I'll post about it in my blog. Sometimes I also make a post of small stuff when there is enough of it. If you're interested in some special thing which you don't understand please open an issue and I'll explain my thoughts.
Some people mentioned a while ago that it might be nice to publish version v0.1.0 even though this project misses a lot of things at the moment. For those of you who are interested in trying things out it should be easier this way. Just ] update in the REPL and you can try the newest stuff.
Okay you should run ] add ConstraintSolver before ;)
That was about a month ago and now ConstraintSolver.jl is already at v0.1.6 so what happened? :D Biggest new feature is the table constraint which I described in this blog a few weeks ago. The rest is basically bugfixes and then v0.1.6 which implements a few new "features".
It's probably best to go through it chronologically as it is a bit of a story.
Oh have you missed my newest YouTube video?
Profiling
After the video I wanted to profile the code to see where the most time is spent. I had a look at my profiling post to check how the commands again. I found that something doesn't run the way I thought it would (actually I didn't think much about it...).
In the Eternity II puzzle there are a lot of x == y constraints and I thought okay I've created the EqualSet constraint a while ago so that will be used. Well no... Of course not. Code does exactly what you typed and not what you intended which will be happening more than once in this post.
EqualSet
It uses the LinearConstraint which is a bit overblown for it. Therefore I decided that x == y will be interpreted as [x,y] in CS.EqualSet(2). Which made my code incredibly...
Yeah you guessed it right: Slow!
Wasn't hard to figure out that my pruning strategy was basically non existent. If x has possible values [2,3] and y [3,4] I returned feasible and did nothing because they are not fixed. Always check whether you can't prune more! ;) Well here the problem was I never really used that constraint...
My idea was first to use intersect but that is exactly the part that was slow based on my profiling before. Therefore I decided to do intersect before pruning to have it correct once and then use the changes of the variables to synchronize them. Which can be implemented quite efficiently by also saving which changes got synched already.
Nothing super complicated. I did some tests and it sometimes seemed to be faster and sometimes slower. More about that a bit later ;)
Benchmarks
Okay let's do some real benchmarks ;)
I found out about PkgBenchmark.jl in the Slack chat or on Zulip maybe. As you might have seen: I don't run benchmarks every time I do something as my current process is a little bit tedious.
The idea here is to have some benchmarks defined in a benchmark folder and you can run those benchmarks on a baseline branch (i.e. master) and your new branch to compare those two.
You can export the results as markdown to obtain something like this:
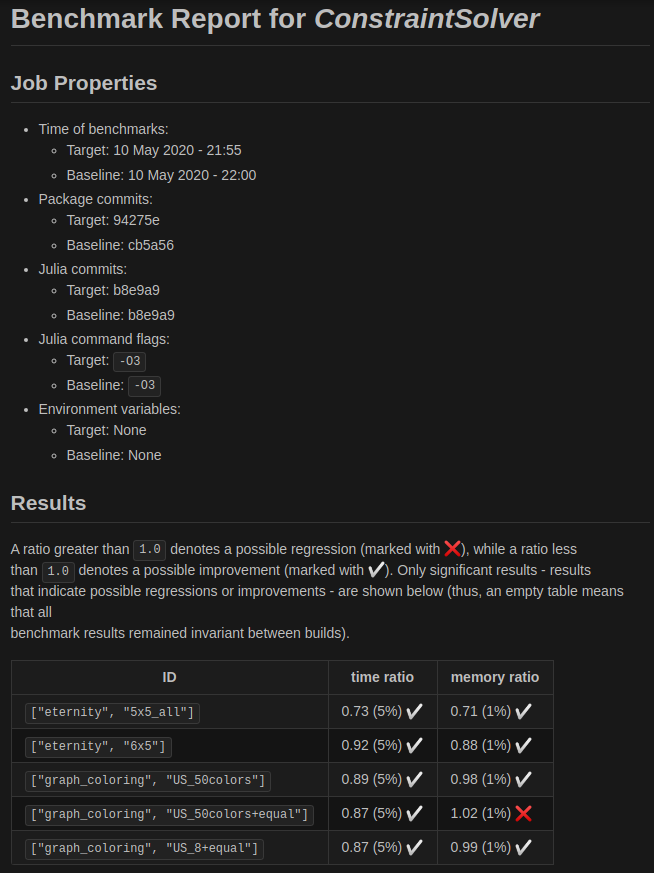
I don't want to wait too long in every benchmark session which uses BenchmarkTools so it runs every task several times. Therefore I had a look at smaller eternity puzzles and found this benchmark set with puzzles ranging from 3x3 boards to 20x20. The original puzzle which has never been solved is 16x16 so I would say there is something for everyone + more.
6x5 seemed like a good benchmark test but it crashed my solver :D Clearly I had a bug or two, three...?
This is another call to myself to write unit tests and probably explain algorithms in more detail on this blog to see that I made a mistake.
Or two, three...? Yeah okay stop it!
There is one function update_table which updates, dependent on which variables changed, a vector which specifies which rows in a table are still valid.
That function has two branches which should do the same thing but one is faster in some cases. One uses the removed values to create a bit mask and inverts it and the other simply takes the still valid values.
Unfortunately the removed values branch called a function which had the docstring:
**Attention:** This does not work if a variable got fixed.and guess what happened. My girlfriend pointed out to me that I should have used an assertion there or just implement that behavior instead of putting it in the docstring. Well I had to agree after probably two hours of tracking down this bug.
Maybe a short note: I later found out that I had a misunderstanding of the function and it should take all removed values and not only the latest removed onces. Which again makes total sense... such that I was actually able to just delete that function :D
You should not trust me with coding at least not in that week... There is a lot to learn from that week. Hopefully I'm getting better.
-> Yeah if you do those UNIT TESTS!
Let me check in which section I am... Ah yeah benchmarking. Good everything went smoothly from here on... for a while.
I've created a benchmark/benchmarks.jl file which has some calls like this:
const SUITE = BenchmarkGroup()
SUITE["eternity"] = BenchmarkGroup(["alldifferent", "table", "equal"])
SUITE["eternity"]["6x5"] = @benchmarkable solve_eternity("eternity_6x5"; height=6, width=5) seconds=60which is quite readable I think. So ["alldifferent", "table", "equal"] are tags and I choose to have the constraints I use as the tags. The last line then defines one benchmark test which has the group name and a benchmark name ["6x5"] and it runs for 60 seconds so a couple of times and returns the timing information which later produces the output you've seen before.
Then I've created some code around this, such that I can run it on my desktop machine and make a comment on a PR kinda automatically. I might try to actually check whether there is a new PR and then let my Raspberry Pi start my computer which runs the tests pushes a comment to the right PR and if there is a comment already update it.
Yeah you could also run it as a GitHub action but I find it more reliable to run it on a dedicated machine. Which is probably overkill for my small project but I don't care.
So you might already ask yourself: What went wrong this time?
Let me point you to the code first ;) run_benchmarks.jl
One can call that script with:
julia ./run_benchmarks.jl -t refactoring-init-fixes -b master -c 625078641 -f ~/Julia/ConstraintSolver/benchmark/results/refactoring-init-fixes.mdWhich compares refactoring-init-fixes with master and saves the result in a markdown file as well as updates a comment with the id 625078641 which points to this comment
To create a new comment one can use --pr 155 for example to create a comment in PR 155.
The real bug
Now I had this awesome tool and ran benchmark after benchmark on my laptop and everything seemed kinda random. I've changed something to make eternity faster and then graph coloring which had nothing to do with my change got significantly slower. Sometimes eternity was way slower and I thought okay it's on my laptop so maybe I do too much stuff in the background.
Well I've run it and chilled my life for half an hour and the results were crap.
Another time for my visual tree debugging tool which is still not published :/
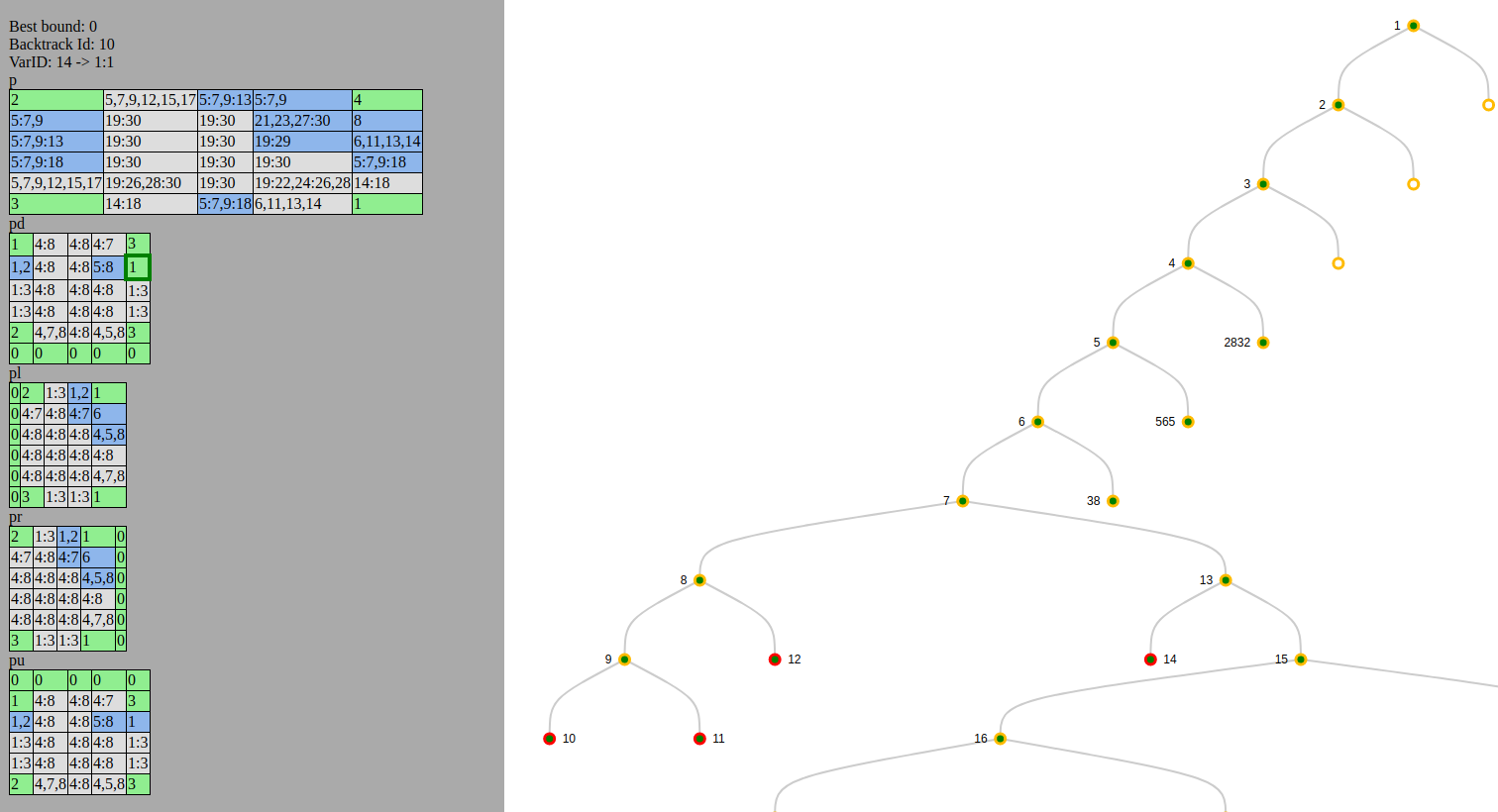
It has some new tiny features since last time I mentioned it. One can see which variable changes (compared to the parent node) in blue and one can hover over the variable to see the internal variable id.
That last point drove me insane for two days. Because that internal id number changed. It was a bit like the bug I had a while ago where some things were random from time to time.
Last time it was a problem in my code which appeared because I haven't initialized a boolean variable and just set it to true when it should be true. It was true before sometimes when it should be false because julia would just take what was in the memory before.
I hope I learned something out of that as it cost me way too much time. This time was different!
I was printing stuff out to track it down and later used a Debugger (see next section) and the results changed. Just wanted to prepare to open an issue at JuMP, the layer below, which seemed to give me those random numbers and then you guessed it: Everything seemed to work fine again.
More benchmark tests and it happened again. Based on my previous debugging week I was unsure whether this is actually a bug in the levels below or in my weird codebase.
Nevertheless after a few questions in the JuMP developer chat whether this is supposed to happen as something unexpected happened also in Gurobi, another solver.
The Gurobi result was weird but seemed to be consistently weird. Later it turned out that there is a good reason why it's not in the 1,2,3,... order the variables where generated it.
It more depends which constraint got called first and which variables are part of the constraint as some solvers somehow don't support it the other way around.
Anyway I was finally able to reproduce the randomness (at least I thought, as randomness can't be really reproduced I guess :D)
Therefore I created a bug report and after several comments and discussions they found the cause of this in the level below JuMP, namely MathOptInterface.
I've created a PR to fix it which will probably get merged soon and will be part of v0.9.14. For now I just use my own MathOptInterface version when I run my benchmark tests.
Wait you wanna know what happened? Okay so the constraints were stored in a dictionary and collecting the keys of a dictionary is not specified as a dictionary doesn't have an ordering. The fix is simply to use an OrderedDict.
I haven't coded much last week it was more like debugging, discussing, opening the issue and the pull request.
Let's come to the last part:
Debugging
I'm one of those developers who likes to debug with println and fellow students would probably agree that I never got used to work with all features an IDE provides. I mostly use it as an editor and a file explorer.
Some of the bugs mentioned above where harder to track down and println doesn't seem to be the best solution such that I tried the Debugger in Juno and in VSCode.
You might wanna checkout Debugging in Juno. Which actually didn't work well for me because it was too slow. All this functionality takes time and I waited for 30 minutes to reach the breakpoint and then I thought "Nah I can't do it that way". There are possibilities like compile mode which should solve that issue somehow but it was probably just too confusing for me.
Someone then suggested Infiltrator.jl to me which is since then my favorite package under 100 stars :D
I mean that name! I love it! The macro is @infiltrate! It kinda brings a story to your debugging experience. You have to infiltrate your own code to get rid of the mess.
Agree it's kinda limited in its functionality compared to a real debugger but damn it's the same speed as just running the code.
You have access to the local variables and can run normal julia command with those variables like printing the search space in a nice grid. It's just awesome. Basically the thing that doesn't work is step by step mode.
I have only one suggestion for it. See this issue which doesn't have any attention yet so maybe YOU have an idea ;) I would like the normal REPL behavior that the up key should give me the last command I used which is currently not the case. It is a custom REPL and it's a bit over my head how to use the Julia REPL functionality to add that.
Anyway I hope you have learned something in this different post. See you next time :)
Next up
How about those unit tests?
Being able to hot start
So provide a partial solution to find a feasible solution faster
If the partial solution is wrong or optimality should be reached then backtrack all the way back
Oh yeah I need to decide on the logo. Please help! Logo issue
Thanks for reading and special thanks to my five patrons!
List of patrons paying more than 4$ per month:
Site Wang
Gurvesh Sanghera
Szymon Bęczkowski
Currently I get 18$ per Month using Patreon and PayPal.
For a donation of a single dollar per month you get early access to the posts. Try it out at the start of a month and if you don't enjoy it just cancel your subscription before pay day (end of month).
Any questions, comments or improvements? Please comment here and/or write me an e-mail o.kroeger@opensourc.es and for code feel free to open a PR/issue on GitHub ConstraintSolver.jl
I'll keep you updated on Twitter OpenSourcES as well as my more personal one: Twitter Wikunia_de
Want to be updated? Consider subscribing on Patreon for free
