Handwritten equations to LaTeX
Creation date: 2018-08-18

This post is again about machine learning and not about optimization but I would like to mention some things beforehand. After my last blog article I started my master's degree in Scientifc Computing at the University of Heidelberg, Germany. During this semester I was also given the opportunity to give a talk about my Juniper project. I was at the CPAIOR conference at Delft for this but there was a stream at the JuMP-dev workshop in Bordeaux. If you're interested in Juniper you might wanna checkout the talk on YouTube.
Anyway now to this blog article. During my class in Object Recognition and Image Understanding I had to choose my own final project and converting handwritten equations to actual LaTeX code was one of my goals for a long time.
Bascially converting things like this: 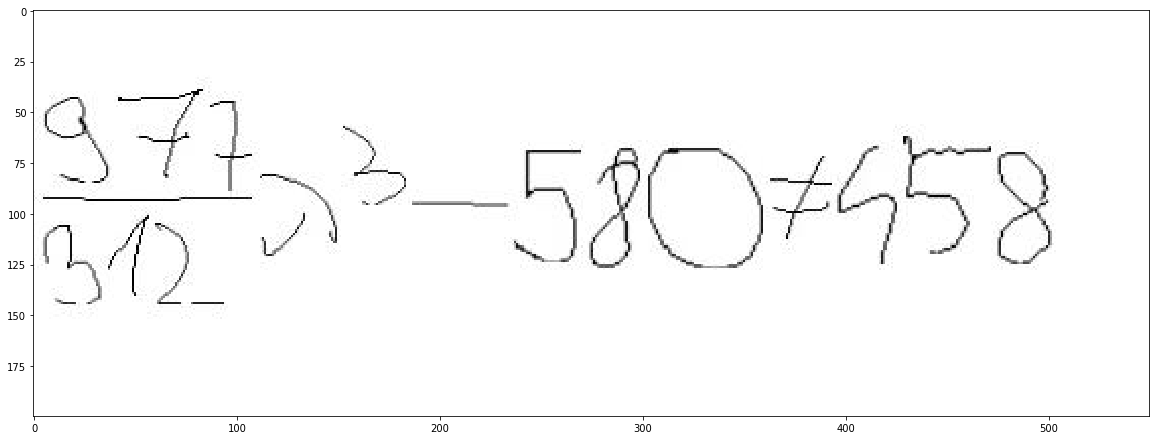
to
$\frac{977}{312}\lambda^3-580\neq 458$which gets compiled to:
\(\frac{977}{312}\lambda^3-580\neq 458\)This blog article should give you a rough idea of how to tackle this problem without giving a state of the art solution.
I used this dataset from Kaggle to get handwritten math symbols.
There are 82 symbols in that dataset but I used only the following for this project:
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '-', '+', '=', 'leq', 'neq', 'geq', 'alpha', 'beta', 'lambda', 'lt', 'gt', 'x', 'y']as the number of examples for each of the symbols was quite good and I had to write my own generator script to construct equations as seen above.
You can find the script I used for generating images on GitHub
It produces only very basic inequalities one with fractions and one without. The next step for me was to train the subset of symbols individually using a CNN in tensorflow. It is pretty similar to their tutorial on MNIST I added an additional convolution and pooling layer and used images of the size 48x48 instead of 28x28 as the images in the dataset are 45x45 but in CNNs they should be divisible by \(2,2^2,2^3,\dots\) depending on the number of layers you have.
I didn't have much information about the dataset on Kaggle therefore I choose to normalize the symbols by using the same steps I used in my previous article about MNIST.
Which means:
I used the bounding boxes of the symbols based on my generator
Scaled/padded the image to 40x40 (preserving the aspect ratio)
Padded it to 48x48
Centered by using the center of mass
Additionally I subtracted the mean of the training images and divided by the standard deviation which is a common procedure to normalize images for CNNs.
For training I used the GPU environment in Google Colab
and this snippet to load the images from GDrive.
The traing using the Tesla K80 GPU was very fast and I achieved a test accuracy of >99%.
This is of course only the first bit of this project. The next one is to find the single symbols in the handwritten equation. My first idea is what I used in my article from two years ago called sliding window this turned out to be completely useless as it is very slow and produces very often false positive results. I'm sure that even two years ago there would have been better approaches. Anyway I tried out the object detection API from Tensorflow which is able to find Objects in real world images. Sounded promising but it turned out that I wasn't really able to make it work on Google Colab and on my computer "with" a AMD Firepro graphics card - don't know how to make it useable for Tensorflow - so without a GPU it took too long and was hard to debug for me.
After some walks and a raised stress level I thought: It's basically black ink on white paper how hard could it be? It's obviously easier than finding a person in front of some weird (natural) background. Sometimes neural networks aren't really the way to go.
Therefore I had a look at OpenCV and found finding bounding boxes using OpenCV
which fits exactly to my problem as it is really fast and easy to implement (calling a function).
What do we have? We are able to find bounding boxes and classify the single symbols correctly most of the time that gives us something like this: 
A few things to these bounding boxes: In general the strokes have to be connected to be part of the same bounding box which isn't the case for \(\lambda\) here and isn't the case for \(=,\leq,\geq\). For the later it isn't really a problem as the \(=\) is basically just two minus signs on top of each other and \(>,<\) on top of a minus sign.
The fraction bar is a long minus sign and for me it was part of the next step to combine these predictions to a real formula.
Here I actually started with handcrafting things which might was a little cheating as I also build the generator and I was of course not satisfied with this option.
My mentor during this project mentioned that I might wanna have a look at sequence to sequence models. That is what I did then in the last couple of days before presenting my project at a poster session.
Sequence to sequence models are models that take one sequence and learn to convert it to another sequence based. This is used for example in translation software. Every word gets an index in a vector as representation (one hot encoding) or a more compact representation (which also can be learned) and then the network is feeded with the input sequence and should output the target sequence. In the learning phase this is done by having the input and the target sequence as the input and the target sequence as the output as the end of the target sequence might depend on the beginning of the target sequence. In the prediction phase this obviously isn't possible as the target sequence is not known. This means that the first word is predicted and that prediction is concatenated to the input sequence to predict the next and so on. There are some techinques i.e. beam search to further improve this step.
I suggest that you read the following articles if you want to know more about sequence to sequence learning:
and/or listen to this talk:
Now I used my generator script to produce the sequences (input and output) which means to decide which information is necessary to produce the LaTeX code. It doesn't only matter which symbols get detected but also the position of those symbols and the ordering in the sequence. My approach was to read the equation top to bottom left to right which obviously isn't the best choice for fractions but wanted to check how good it actually works as the model should learn it. Then I used the absolute position in a range from 0 to 1 of the symbol as well as the relative position to the symbol before which is useful for things like powers as well as the height and width of the symbol (normalized as well) which is reasonable to get that a long minus sign might be actually a fraction stroke.
That training was quite fast on my computer without the need of a graphics card and produced relatively good results.
I used two measurements of accuracy one is how much of a sequence is correct so if the target sequence is: \(1234\) but the output is \(1324\) then it's to 50% correct as the 1 and the 4 are correct. The other measurement is how often is the whole sequence correct.
The former accuracy is about 95% which is also due to the fact that the sequence \(1234\) actually is a \(1234\quad\) so it has some additional spaces in the end which normally gets predicted correctly. The more strict accuracy without spaces is about 85% and about 60% of the sequences are completely correct which itself can be split into two categories the one without fractions had an accuracy of 80% and the one with fractions only 40%.
If you're interested in state of the art solutions I would suggest to read this paper:
Image-to-Markup Generation with Coarse-to-Fine Attention which uses a different representation of the sequence by not actually using the symbol predictions from the CNN but using the last convolutional layer instead and a better sequence to sequence model than the basic one I used here.
My code is again available on GitHub.
If you've enjoyed this and some other posts on my blog I would appreciate a small donation either via PayPal or Patreon whereas the latter is a monthly donation you can choose PayPal for a one time thing. For the monthly donation you'll be able to read a new post earlier than everyone else and it's easier to stay in contact.
Want to be updated? Consider subscribing on Patreon for free
