EverySingleStreet.jl: Map matching
Creation date: 2023-02-05

In the last post we've learned how to download data using LightOSM and visualize it as well as working with .gpx files. This post will be all about map matching which is the process of matching a GPS track to an underlying map.
This means we will obtain the information of which street or more precise which segments of each street we already walked. That is probably the most important step in our problem of tracking the every single street progress.
Introduction
Last time I gave a very rough intuition of the problem and an idea of how to solve it. Let me describe it again in a bit more detail and with some visualizations.
Here you can see a map and an overlayed GPS track which has some noise and sometimes has quite a gap between two points.
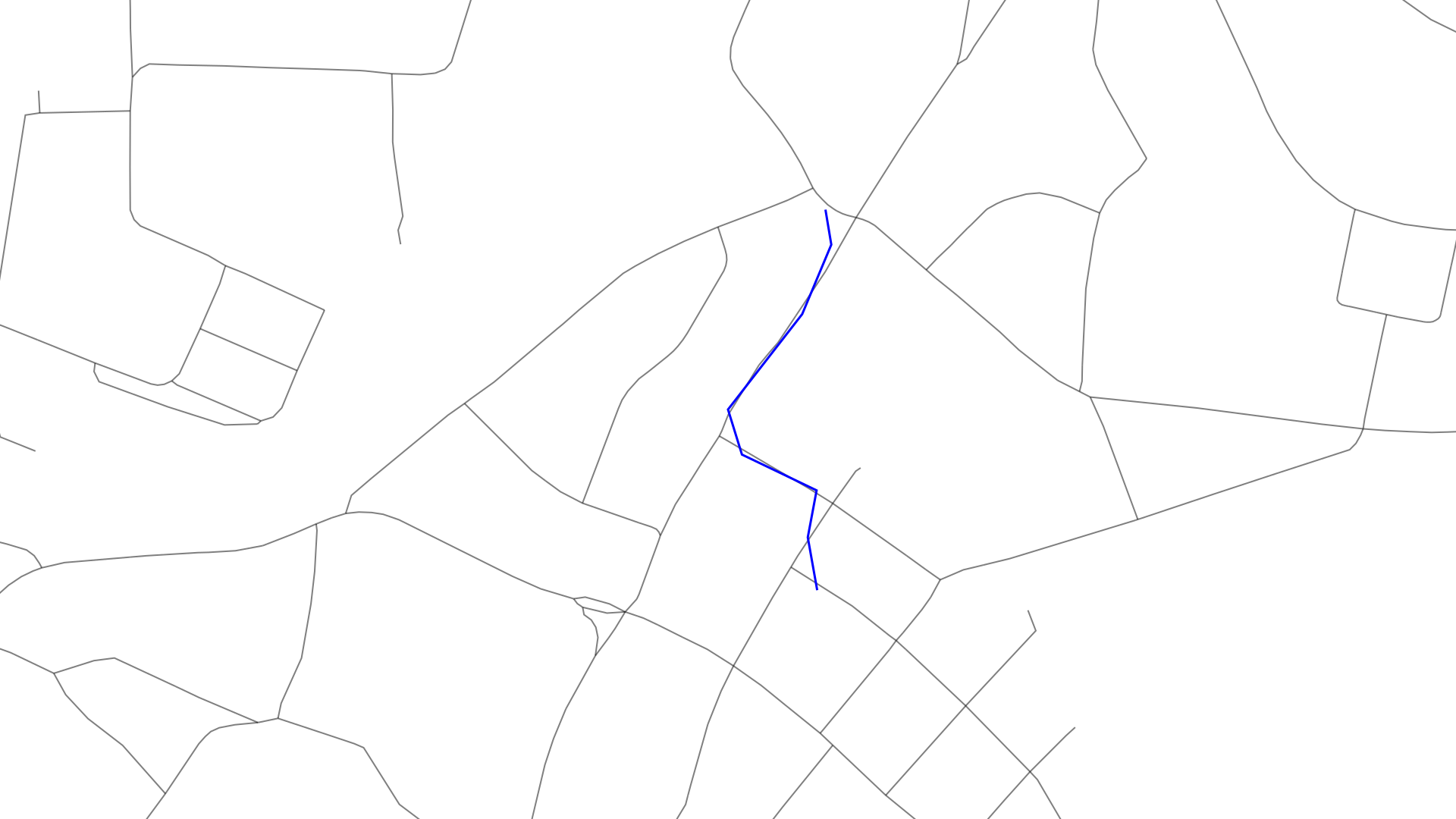
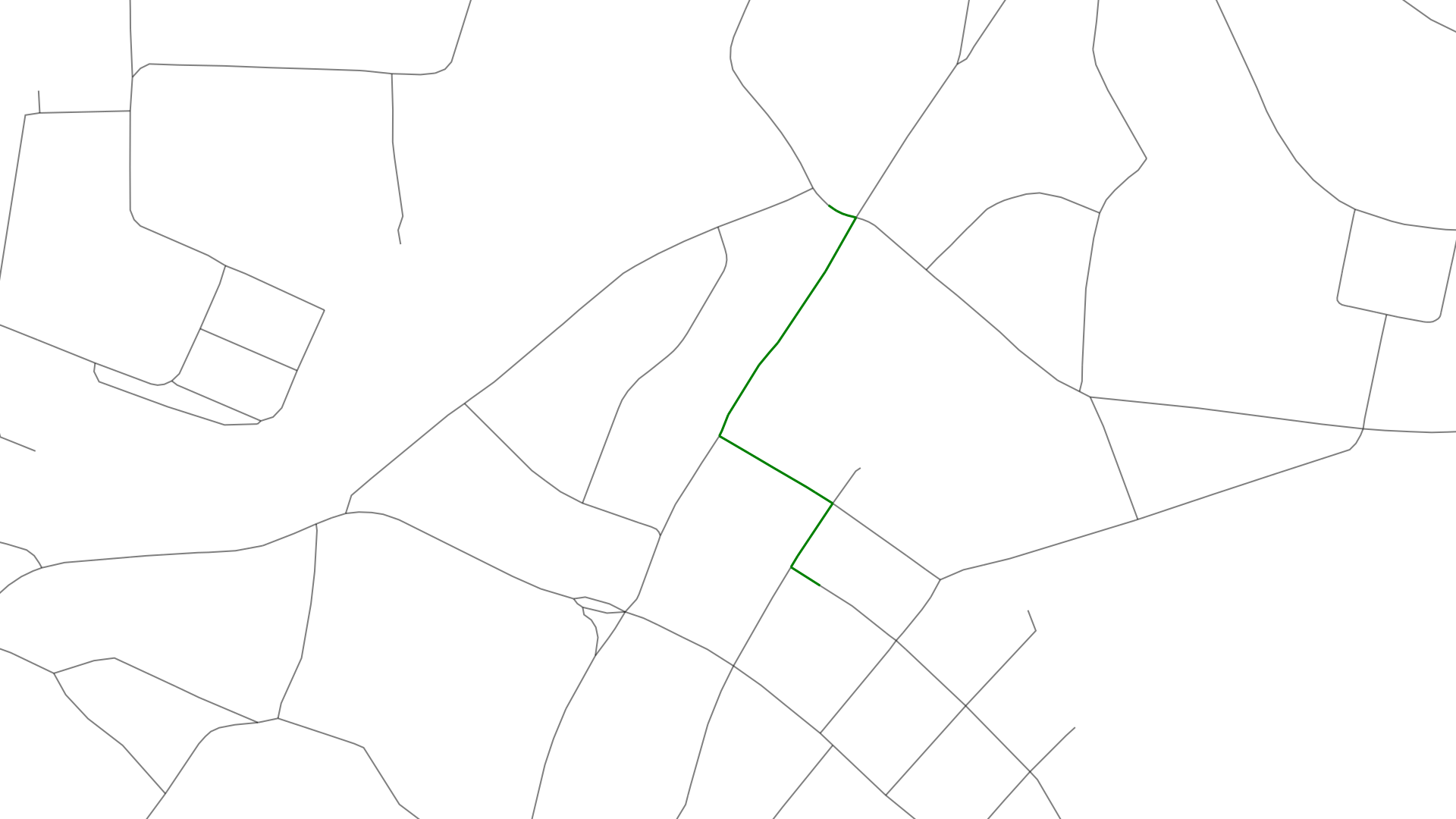
The goal of map matching is to generate the green path out of the above:
This process involves several steps
get candidate points for each GPS point were each candidate point is a point on the underlying map
based on the full GPS track compute the candidate points which fit together based on the structure of the map
combine those best candidates to a route on the map
Candidate points
Each GPS point on the track gets a list of candidate points on the map. A candidate point is a point on a way which is closest to the given GPS point based on point to line segment distance. One can give the maximum distance basically a search radius for those candidates.
In this graphic you can see a bunch of candidate points (green) for a single GPS point (blue). Some of these points are actually on the same position they just map to a different way/street. The street just north of the initial GPS point is split up into two segments of the same way that's the reason why we have two green points on the same street.
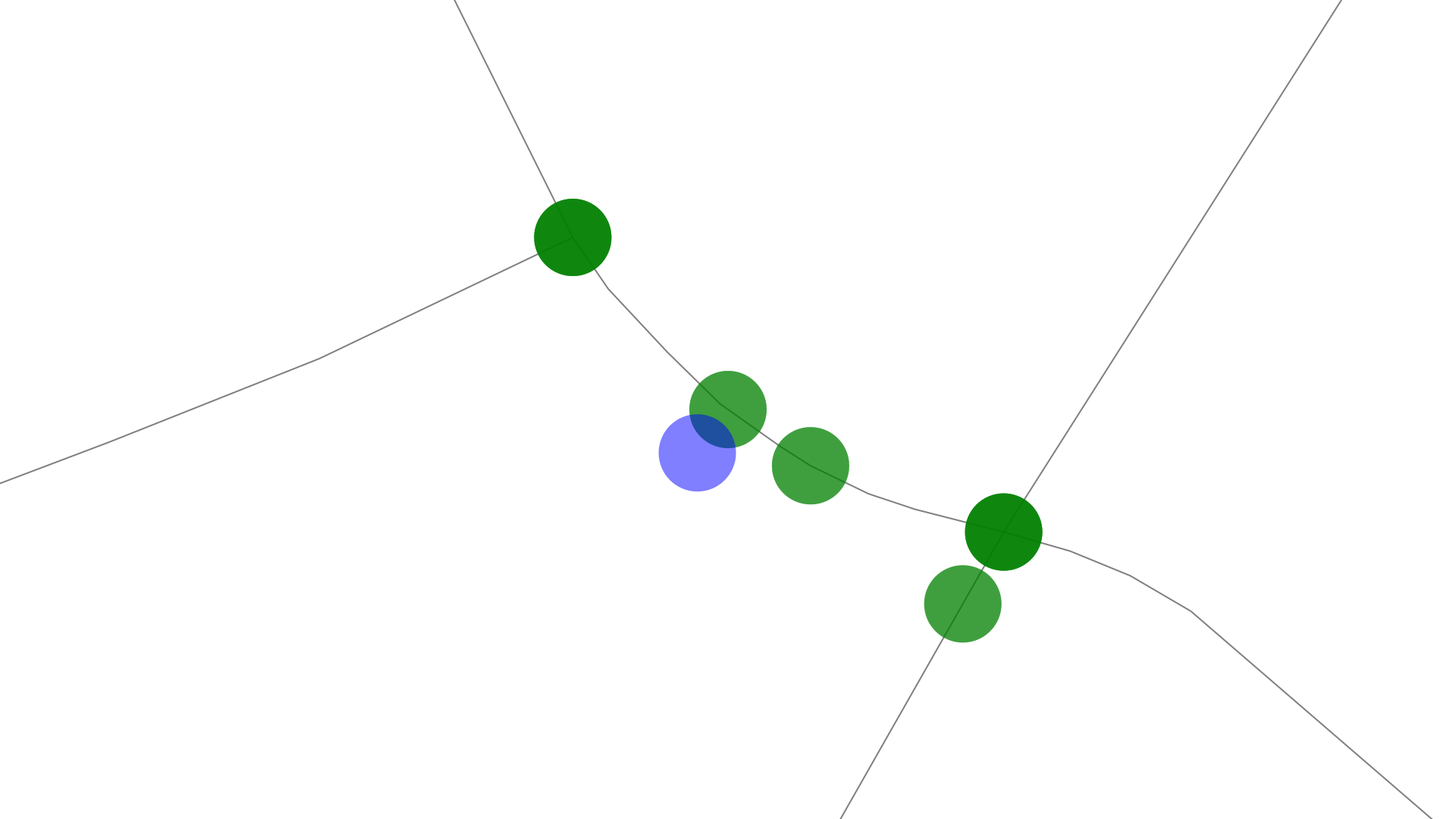
For each of these candidates we store information like: the GPS position, the street it is on, the distance to the original point as well as how far along the road we travel to get to that point. This is later used for calculating the length of the walked path.
Hidden Markov Model
With the above we have information about likely points were we actually started with our track as well as candidates for our positions in between. With a hidden Markov model (HMM) we now try to find the best candidate for each point in a way that they create a consistent picture for the full path.
Before I go into the detail let me give an introduction to HMMs first. A HMM consists of a state network where each edge has a probability attached to it that gives information of how likely it is to make the transition from the current state via that edge to the next state.
 By Terencehonles - Own work, Public Domain, https://commons.wikimedia.org/w/index.php?curid=8384168
By Terencehonles - Own work, Public Domain, https://commons.wikimedia.org/w/index.php?curid=8384168
That state network can look like the upper part of the above graphic. Here we start with a 60% probability with the state "rain" and a 40% chance of starting in the sunny state. The network itself describes the transitions from two weather states from one day to the next. It is assumed/calculated that there is a 70% chance of having a rainy day if the previous day was also a rainy one and a 30% probability of having a sunny day if the previous day was rainy and so on.
What is described here are assumptions about how the world works but we never really get data about the weather directly as this is the hidden part of the model that we want to predict. Now how do we predict it? We have a look at the things we can observe which is described by the three possibilities in the lower part of the graphic namely walk, shop, clean.
Maybe a bit of a step back on the tale behind that graphic 😄 There are two people Alice and Bob. Bob tells Alice every day what he did that day and Alice wants to make the best assumption possible on the weather Bob had those days based on a list of those activities. Assumptions: Bob only does one activity per day, the weather depends on the weather of previous day but not of the weather of the day before that.
Now Alice has an idea of the general weather pattern as described above but also a probability assumption on how the activities of Bob depend on the weather. For example if we have a rainy day then Bob has a 10% chance, he is likely to clean with a probability of 0.5 and the rest likelihood goes to he is shopping on a rainy day.
With this network one can make assumptions of how likely a given weather pattern was based on a given set of activities. Hidden Markov Model explained on YouTube by Normalized Nerd
It is also possible to compute the most likely weather pattern with this network.
I don't want to and can't, due to lacking knowledge, go into too much detail on HMMs and rather want to show how this model can help us with the map matching problem. If you want to read a detailed paper on this after this post please check out the fast map matching paper. That was my main source of this when implementing it in Julia for my EverySing;eStreet.jl project.
What we need to use HMMs for our project is to compute the probabilities of the state network. In our case the nodes at the top will be our candidate nodes which are hidden as we don't know and want to compute which candidate is the one we most likely passed on our walking trip. The transition probability between two candidates depends on the shortest path (using the map) between two candidates and we only want to compute those between candidates of one GPS point to the next.
Then we need to compute the so called emission probabilities which are the probabilities that connect the candidates to the actual measured GPS points. Those depend on the distance from the measured point to the candidate point. In our case one candidate point maps to only one measured point but one measured point has several candidate points. One gives the probabilities in the direction of candidate point to measured point though which is the reason why I created an extra node in the observed nodes space which has an arrow from each candidate point to it such that the probability from one candidate point to a measured point is based on the distance and not just 100% because it's the only possible connection. I was unable to figure out how they solved this in the mentioned paper or whether there are different definitions of how a HMM can be formalized in.
In Julia I use the package HMMBase.jl to describe the state network and solve for the most likely path in the state network.
Currently my implementation is relatively slow as I don't precompute the shortest paths yet which is the main point of speedup described in the paper which is definitely worth a read!
Create the segments
With the above solved we get a list of candidate points like this:

These are the most likely points for our measured GPS path. The next step now is to combine those points into a path. For this I created struct StreetSegment which consists of two candidates but those candidates need to be on the same street and the street needs to be in the same direction. The second part is to easily compare the distance from the start point to the point on the street which we save for each candidate.
For this we compute the shortest path again between the candidates we calculated and insert new candidates in between to fulfill the above property and to create
Then we'll have all the data we need to compute which street segments we have already visited, how many percent of the streets we already walked and so on.
Conclusion
We are able to use the Hidden Markov model to convert a bunch of messy GPS data with some error to a map such we have a good guess of which streets were walked. Some things we have to deal with in the future are errors in this map matching when paths we walked aren't on the map and the shortest path is longer than something we could have walked in a given time frame. Additionally adding the precomputation step with speed up the map matching process.
Hope you learned something along the way and thanks for reading!
Special thanks to my 9 patrons! Thanks so much for you continued support on my journeys in open source and tackling those projects.
Special special thanks to my >4$ patrons. The ones I thought couldn't be found 😄
Gurvesh Sanghera
Szymon Bęczkowski
Colin Phillips
Want to be updated? Consider subscribing on Patreon for free
