Juniper workflow
Creation date: 2019-03-06

This blog post is mainly about the workflow I've learned during my time as an intern at the Los Alamos National Laboratory where I programmed a solver for Mixed Integer Non Linear Problems (MINLPs) the solver is called Juniper.jl. I think it is quite useful for your own projects as well as projects in company. Some of you might already do this in one way or another but others might get some interesting ideas. I'll use julia as the programming language for some explanations here as I think it will be easy to follow and for a lot of other programming languages there are many tutorials out there.
Test-driven development
It basically means that you first write your tests before you start coding. It is beneficial in some different ways. First of all if you keep doing this you can't really forget to write tests as you have to before you start coding. In general tests are necessary to keep track of what works and what doesn't and some future changes might have an impact on your previous work and in some circumstances it might ruin it without that you even think about it. Additionally if you work with some teammates you might sometimes have a different view and don't think too much of what the other person thought when coding a part and you might break it with your new function which should make everything better and faster but there might be an edge case you missed. Furthermore you should of course document your code.
In Julia you would need to create a package similar to this tutorial which creates a test folder and test/runtests.jl which includes all your test cases which might look like this:
using TestPackage
@testset "test 1" begin
a = 2
b = 2
@test TestPackage.add(a,b) == 4
endwhich of course is a stupid test case and you might think that you want to use random numbers each time but be warned: Randomness is almost always something you don't want to use as it's very hard to debug.
Some things which might be interesting for your Julia project:
@test isapprox(a, b, atol=1e-5)which tests whether a is approximately b with an absolute tolerance of \(10^{-5}\). rtol for relative tolerance.
You might have Julia v1 installed on your machine but v1.1 is already out. Some time later you have v1.1 installed then the next version is coming soon and of course you hope that your project still works in v1.2 but also v1 as some people might be still using that version. It's very tedious to install all versions on your machine and maybe you want to test it on Mac as well but you don't have one at home. That's why you probably want to use Travis which tests your code on all the versions you want whenever you push it to GitHub.
For this you need a .travis.yml file in the root folder of your project which looks similar to this:
language: julia
os:
- linux
- osx
julia:
- 1.0
- 1.1
cache:
directories:
- /home/travis/.julia
addons:
apt_packages:
- gfortran
before_install:
- julia -e 'using Pkg; Pkg.update()'
script:
julia -e 'using Pkg; Pkg.clone(pwd()); Pkg.test("TestPackage", coverage=true)'
after_success:
julia -e 'using Pkg; Pkg.add("Coverage"); cd(Pkg.dir("TestPackage")); using Coverage; Codecov.submit(process_folder())'This will test your package TestPackage on linux and osx with Julia v1.0 and v1.1. here it also checks which lines of your code are covered using Codecov an awesome tool to check which part of your code is never called and maybe it's unnecessary or you might want to add a test case for that.
Performance tests
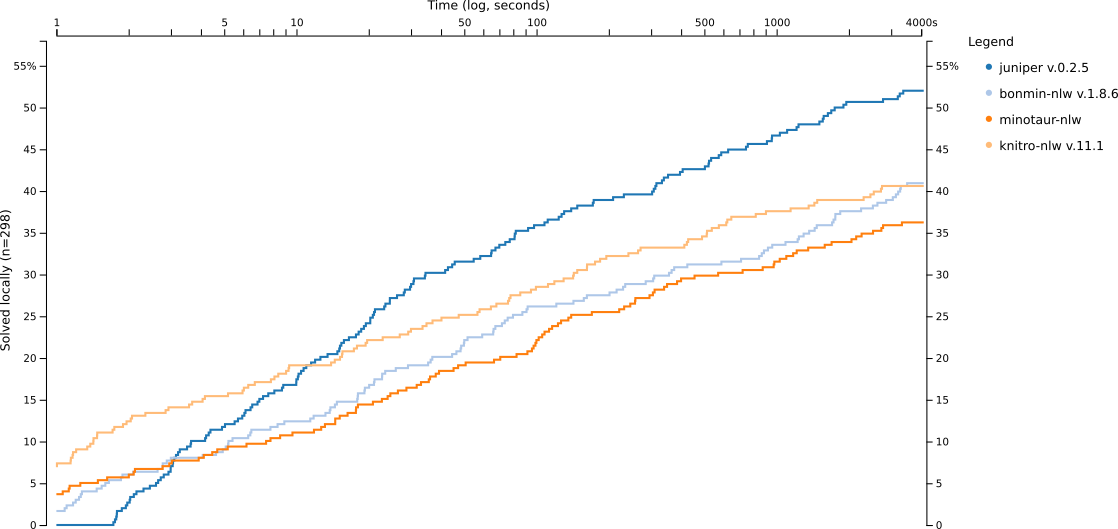
Your test cases are normally just checking whether your code works but not whether it is efficient and you might think that you can have a test like timing the function and it should take less than 10 seconds but the travis platform might be not as fast as your own machine and you don't want that the test fails because it takes 11 seconds on their machine sometimes. In addition the normal test cases should run rather quickly as you might run them often when you change something in your code. For Juniper we have around 300 test cases which we also used to check our performance against other MINLP solvers in our paper. There we checked how many test instances can be solved within an hour and how fast. A bit less than 50% can not be solved by any of the solvers in this time frame which means that it takes >150 hours (the other test cases need some time as well) to run those instances on one core. Of course it can be done in parallel but it still takes quite a while. For me I run ~170 locally on 6 cores from time to time which takes about 6hours. These tests are crucial if you make bigger changes to your project which might not affect your normal test cases (they shouldn't) but make the project faster or slower and sometimes unexpectedly.
Visualization
I'm doing this to check the data produced by the performance tests. In some cases it might be just about speed and you want to have a line graph comparing it to previous versions of your program and to other programs solving the same problem. That's what I'm publishing here and you can find the code on GitHub.
Debugging information
You might normally do some step by step debugging to debug your code but what I mean here is something different. In Juniper everything depends on the instance you try to solve and there it is one thing to show the user what is going on during the process but it might be also relevant to check exactly what happened with much more information than normally relevant for the user. For Juniper it can be used to build a tree structure for the branch and bound tree for example and having a visualization of which node was traversed next. It can also be used to write some more advanced test cases.
Hope you learned something useful in this post and maybe you want to check out the Juniper project.
If you've enjoyed this and some other posts on my blog I would appreciate a small donation either via PayPal or Patreon whereas the latter is a monthly donation you can choose PayPal for a one time thing. For the monthly donation you'll be able to read a new post earlier than everyone else and it's easier to stay in contact.
Want to be updated? Consider subscribing on Patreon for free
