Multiplicative persistence with Julia
Creation date: 2019-03-21

I came across the following YouTube video by Numberphile today:
It is about multiplicative persistence which means roughly the following. We take an integer and multiply the digits together to get a new number. This will be done in a loop until we get a single digit number. Example: 3279->378->168->48->32->6. The persistence of 3279 is 5 as it takes 5 steps.
Currently we only know numbers with a persistence of up to 11. The smallest number with this persistence is 277,777,788,888,899. The community is only interested in the smallest number. Therefore, \(3279\) is not really interesting as \(2379\) has the same persistence and is smaller. FYI: 679 is even better and the smallest with a persistence of 5.
You can find the list in the on-line encyclopedia of integer sequences oeis.
Mathematicians think that there is no number with a higher multiplicative persistence than 11. They tested it with all reasonable numbers up to over 230 digits.
Anyway I wanted to give it a try. In the video Matt Parker writes some code as well to get the persistence of a number in Python. I used Julia ;)
Matt used recursion which would look like this in Julia:
function per(x; steps=0)
if x >= 10
return per(prod(digits(x)); steps=steps+1)
end
return steps
end**More elegant solution: ** (mentioned by Jolle in the comment section)
function per(x)
x < 10 && return 0
return 1 + per(prod(digits(x)))
endThen you don't need the steps parameter and it is very easy to read.
Yes digits and prod are standard functions in Julia.
We can easily test the performance when we use BenchmarkTools
using BenchmarkTools
@btime Persistence.per(277777788888899)
845.794 ns (11 allocations: 1.45 KiB)
11and we know that we probably don't get in trouble with too many recursive calls as our expected limit is a persistence of 11 but it is also not really necessary and can be avoided by using:
function per_while_simple(x)
steps = 0
while x >= 10
x = prod(digits(x))
steps += 1
end
return steps
endwhich has a similar performance.
@btime per_while_simple(277777788888899)
832.013 ns (11 allocations: 1.45 KiB)
11now we have a problem that currently we are dealing with normal integers which doesn't work if we actually want to deal with large numbers (like 230 digits...).
We have to change prod(digits(x)) to prod(convert.(BigInt,digits(x))) in both functions. This increases the runtime to \(\approx 18 \mu s\)
We can try it with a very big number:
27777778888888888888888888888888888888888888888888888888889999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999which has 230 digits. This takes \(\approx 170 \mu s\).
Let's generate some numbers and compute their persistence.
We call the function function create_list_simple(;longest=15) and start with this code. BTW: longest means the maximum number of digits we want to create.
best_x = 0
best_s = 0
n = zeros(Int, 8) # from 2 to 9
start_time = time()Our current best one is 0 with 0 persistence. We store a number based on the fact that we only care about the smallest number in the following way: n stores how often a digit is used. \(0\) and \(1\) are useless as a \(0\) is always bad for persistence and a 1 can be removed. Now an example for \(n\) can be [1,0,0,0,0,6,6,2] which represents the number 277,777,788,888,899. All the interesting numbers have this ascending structure so we can store them this way. The next parts will get into a while True loop.
for d in 8:-1:3
if n[d] < longest-(sum(n)-n[d])
n[d] += 1
break
end
n[d:8] .= 0
endMy idea was to create numbers in this form like normal counting in our n array structure. So we first have 9 then 99 and so on until we have 15 of them then we get to 8,89,899 etc. This implies that we don't create our numbers in an ascending order.
We do this only down to 4 as \(2 \cdot 2 = 4\) so we could make the number smaller same principle for \(3\). Attention: 8:-1:3 creates 8,...,3 but we store it in our special structure where we don't save the 1 so 3 corresponds later to 4.
In the end our n would be [0,0,0,0,0,0,0,0] then we want to add a 3 at the front and after that a 2.
if all(i -> i == 0, n[3:8])
if n[2] == 0
n[2] = 1
elseif n[1] == 0
n[1] = 1
n[2] = 0
else
println("Checked all")
break
end
endthen we check if there is a 2 and a 4 as this could be again reduced to \(8\).
if n[1]+n[3] < 2
x = arr2x(n)
s = per_while_simple(x)
if s > best_s || (s == best_s && x < best_x)
best_s = s
best_x = x
println("Found better: ", x , " needs ", s , " steps and has a length of: ", length(string(x)))
end
endThe arr2x function creates the actual number out of our array:
function arr2x(a::Vector{Int})
str = ""
for i in 2:9
str *= repeat(string(i), a[i-1])
end
return parse(BigInt, str)
endafter closing the while loop we can print how much time it took:
println("Time needed in total: ", time()-start_time)julia> Persistence.create_list_simple(;longest=15)
Found better: 99 needs 2 steps and has a length of: 2
Found better: 999 needs 4 steps and has a length of: 3
Found better: 9999999 needs 5 steps and has a length of: 7
Found better: 8899999 needs 5 steps and has a length of: 7
Found better: 888899 needs 6 steps and has a length of: 6
Found better: 888888 needs 6 steps and has a length of: 6
Found better: 888888888 needs 7 steps and has a length of: 9
Found better: 77788899 needs 8 steps and has a length of: 8
Found better: 7777788999 needs 9 steps and has a length of: 10
Found better: 6668888888888 needs 10 steps and has a length of: 13
Found better: 6667788899 needs 10 steps and has a length of: 10
Found better: 666677777788888 needs 11 steps and has a length of: 15
Found better: 466777777888889 needs 11 steps and has a length of: 15
Found better: 367777778888889 needs 11 steps and has a length of: 15
Found better: 277777788888899 needs 11 steps and has a length of: 15
Checked all
Time needed in total: 1.5783820152282715We found our \(277777788888899\) which is satisfying. I know it was checked for over 200 digits but let's see how long it takes for 40 digits... It checks \(6,404,978\) numbers in 440s on my machine.
Can we do better?
If we increase the number of digits in a number we have to do a lot of \(9^x\) calculations. My idea was to precompute those numbers.
global cache
function create_cache(;longest=240)
global cache
cache = Vector{Dict{Int,BigInt}}()
for d = 2:9
cd = Dict{Int,BigInt}()
for i = 0:longest
cd[i] = d^convert(BigInt,i)
end
push!(cache, cd)
end
endIf we call that function we create a cache for each digit with up to \(x^{240}\).
Now we create our n structure back from a number and calculate the next number using that structure.
function per_while(x)
steps = 0
n = zeros(Int, 8) # from 2 to 9
while x >= 10
list = digits(x)
for l in list
if l == 0
return steps+1
end
if l > 1
n[l-1] += 1
end
end
x = prod_arr(n)
n[1:8] .= 0
steps += 1
end
return steps
endprod_arr is defined as:
function prod_arr(a::Vector{Int})
global cache
n = ones(BigInt, 8)
for i=2:9
n[i-1] = cache[i-1][a[i-1]]
end
return prod(n)
endIf we use this function instead we can calculate all reasonable numbers in about 300s.
In general there are options to further reduce the search space. ;)
I also created a small visualization of the persistence of the numbers up to 100.

Additional second part
I thought about this again after published it and improved the style and performance of the code. Additionally I created some more visualizations.
Problems with the version I explained above about creating a list of numbers is that it doesn't generate them in ascending order. Like 666677777788888 before 277777788888899 for this I actually got rid of the n structure and created a list in a different way. This might be not the best way according to what I saw on Twitter but I think it's alright. The thing that is changing is inside the while True loop. We initialize a variable x=BigInt(1) before which represents the number we want to test.
x += 1
sx = string(x)
# keeping track of the current length of the number
if x >= 10^convert(BigInt,current_length)
current_length += 1
println("current_length: ", current_length)
endSo we increment it by one each time and whenever it gets bigger than the current_length we increase it and have a little output. This would now produce 2,3,4,5,6,7,8,9,10,11,... now we want 2,3,4,5,6,7,8,9,22,23,... instead.
if sx[end] == '0'
# if the number is 10...0 then the next reasonable one is 22...2
if sx[1] == '1'
x = parse(BigInt,"2"^current_length)
else
# check how many 0 we have in the end like 2223000 after 2222999
# then the next reasonable is 22233333
tail = 1
while sx[end-tail] == '0'
tail += 1
end
front = sx[1:end-tail]
back = front[end]
x = parse(BigInt,front*back^tail)
end
endWhenever we have a 0 as the last digit we check whether we got a 10...0 or just sth. like from 229 to 230. In the first case we jump to 22...2 in the other case we check how many zeros we have and then replace it accordingly like from 229 directly to 233 and from 2399 to 2444. Our check for break is then:
sx = string(x)
if length(sx) > longest
println("Checked all")
break
endRunning the program now creates:
current_length: 2
Found better: 25 needs 2 steps and has a length of: 2
Found better: 39 needs 3 steps and has a length of: 2
Found better: 77 needs 4 steps and has a length of: 2
current_length: 3
Found better: 679 needs 5 steps and has a length of: 3
current_length: 4
Found better: 6788 needs 6 steps and has a length of: 4
current_length: 5
Found better: 68889 needs 7 steps and has a length of: 5
current_length: 6
current_length: 7
Found better: 2677889 needs 8 steps and has a length of: 7
current_length: 8
Found better: 26888999 needs 9 steps and has a length of: 8
current_length: 9
current_length: 10
Found better: 3778888999 needs 10 steps and has a length of: 10
current_length: 11
current_length: 12
current_length: 13
current_length: 14
current_length: 15
Found better: 277777788888899 needs 11 steps and has a length of: 15which creates the correct integer sequence (oeis).
For this I removed the checks whether it is reasonable so it creates 222 as well even if it can be reduced to 8. These kind of checks are now generalized in my code in the cache part.
### check for up to 10^power whether the digits are reasonable
# i.e 22 is not reasonable as 4 is smaller same with
power = 7
next_possible = zeros(Int, 10^power)
smallest_possible_for_x = 10^power*ones(Int, 9^power)
l = length(smallest_possible_for_x)
last_i = 1
for i=1:10^power
m = prod(digits(i))
# if it ends in 0 => not reasonable only for step 2
if 0 < m <= l && m % 10 != 0
if i < smallest_possible_for_x[m]
smallest_possible_for_x[m] = i
next_possible[last_i+1:i] .= i
last_i = i
end
end
end
smallest_possible_for_x[1:9] = collect(1:9);The important array here is next_possible which is an indicator whether a number is reasonable. For example next_possible[222] is 255 which means that 222 up to 249 all numbers are not reasonable. 222 as mentioned is the same as 8, 223 is the same as 26 and so on up to 249 which is the same as 89. I save this up to 7 digits. If a number is reasonable i.e 26 then next_possible[26] equals to 26. The extra check && m % 10 != 0 is for something like 25 which creates a 0 in the end and is definitely useless so we consider it as not reasonable. This removes 25 from our list with a little sad but I'm okay with it :D
Later we use this to jump to the next useable number:
first_digits = parse(Int,sx[1:min(length(sx),7)])
if next_possible[first_digits] != first_digits
# jumping to the next reasonable number
first_digits = next_possible[first_digits]
x = parse(BigInt, string(first_digits)*string(first_digits)[end:end]^(current_length-length(string(first_digits))))
endWith this improved code we can check the numbers with up to 40 digits in \(\approx 60s\) which is 5 times faster than the 300s we had before.
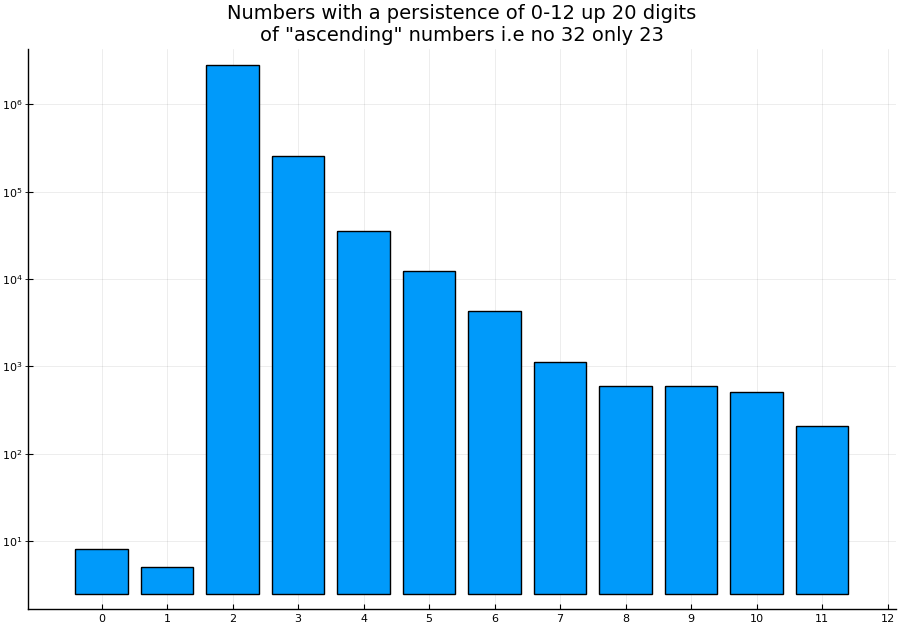
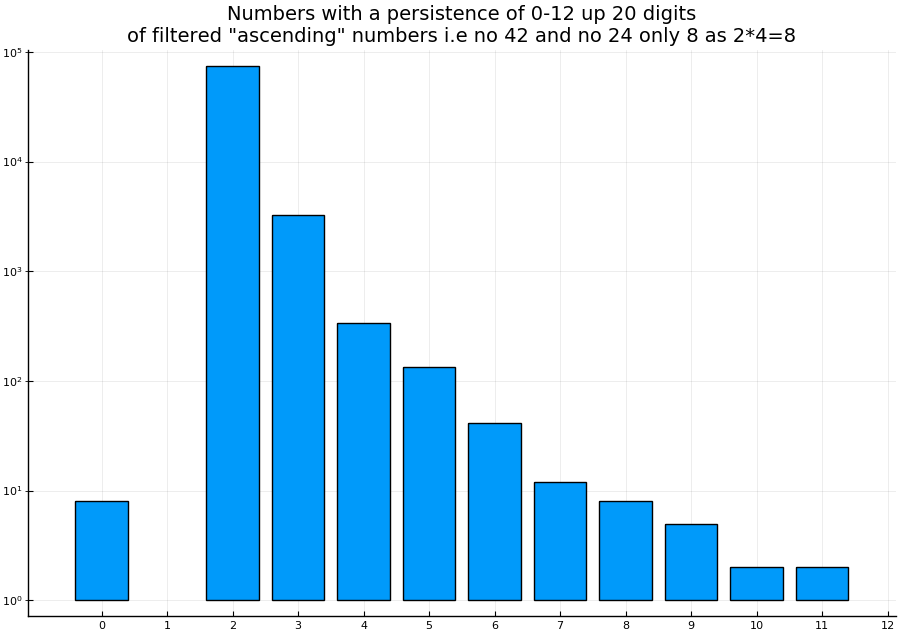
I read somewhere that it would be nice to have a histogram as well so I plotted it:
The first one shows the first version of the improved code (without the filtering check)
the next one shows the histogram with up to 20 digits as well but uses the filtering step.
Additional third part
There is another performance update again mentioned by Jolle in the comment section below. Creating unnecessary arrays is quite bad and I was just too lazy by using the default function digits.
Instead using this function:
function digitprod(x::T)::T where {T<:Integer}
val = one(T)
ten = T(10)
while !iszero(val) && !iszero(x)
(x, r) = divrem(x, ten)
val *= r
end
return val
endWhich takes a number x of some kind of type integer and then computes the digits itself by dividing it by 10 and then taking the remainder and continue with the rest. This doesn't create arrays each time and is therefore quite a bit faster. Running my test again with all reasonable numbers up to 40 digits it takes now \(\approx 25\)s instead of 60s. It also doesn't really matter whether we use the more complicated cache version or the simple while version then.
There are some other people who saw the video on Numberphile and programmed their own version. They specialized more on performance and on interesting ideas how to reduce the search space. Please have a look at the code by Amit Moryossef on pastebin who is also trying to prove that there is no number with a persistence of 12. I'll definitely keep you updated on that. Additionally please check out the code by Davipb which is written in C. He mentioned on Reddit that he checked it up to 400 digits.
Edit 31.03.2019 If you're interested about the newest code projects and findings you might wanna check /r/numberphile. There I found this database of numbers with a persistence of >2 up to a huge amount of digits Multiplcative persistence DB
The code for the visualization with d3 as well as the Julia code is on my GitHub.
I'll keep you updated if there are any news on persistence on Twitter OpenSourcES as well as my more personal one: Twitter Wikunia_de
Thanks for reading!
If you enjoy the blog in general please consider a donation via Patreon. You can read my posts earlier than everyone else and keep this blog running.
Want to be updated? Consider subscribing on Patreon for free
